原文链接: http://www.juzicode.com/computer-basis-encoding-windows-bug/
桔子菌:你听说过微软30多年前推出Windows的时候,隐晦表达过联通不行移动行么? 橙子妹瞟了一眼桔子菌:瞎扯,我只听葛优说过“神州行我看行”。 桔子菌有点炫耀:不可思议是吧?你看我用Windows7自带的记事本软件新建2个txt文件,在文件中分别输入“联通”和“移动” ,再次打开文件看,发现保存了“移动”的文件仍然可以看到“移动”2个字,但是保存“联通”的文件就不行了,看不到了。 橙子妹稍微有点惊讶,又瞟了一眼桔子菌:你这是哪跟哪,不过我还是有点好奇这是怎么回事。 桔子菌:请听我娓娓道来。
在计算机的世界里,不管是内存、硬盘存储的内容都是“0”和“1”,网络上传输的数值也是“0”和“1”,CPU能处理的也是“0”和“1”。单个bit只能表示”0″和”1″的2种数值状态,通过bit位数的增加就可以表示更多的数值。通常用8个这样的”0″或”1″构成一个字节,这样一个字节就包含了256种数值,再进一步的2个字节就能表示65536种数值。这些数值表达什么含义,或者这些数值之间按照特定的关系进行”组织”,这个“表达”或者”组织”的过程就叫做编码。
如果要将这些字节再按照相反的顺序表达出来,就是”解码”的过程,经过特定的解码方法就能得到特定的内容。比如在一张bmp图片文件中,文件中存储的数值表示各个像素点的亮度值,而在一个文本文件中,这些数值存储的就是一些字符。怎么区分一个文件到底是图片文件还是文本文件,一般是根据文件的后缀名称来区分的。在Windows操作系统里,双击一个”.bmp”文件,系统就会根据后缀”.bmp”去查找默认的图片程序打开这个文件,双击一个”.txt”文件,就会根据后缀”.txt”找到对应的文本程序打开这个文件。此处如果抬杠的话,你要用文本程序打开图片文件也是可以的,只是并不能得到你想要的东西。
到了这里我们清楚了不同的后缀可以对应特定的应用程序来打开,但是有些文件即使是相同的后缀,可能他内部的格式还是有差异的,这又是怎么区分的呢?比如一张bmp文件,到底表示的是黑白图片还是彩色图片、彩色图像是用16色(4位)还是24位表示的,仅仅通过后缀已经不能区分了。
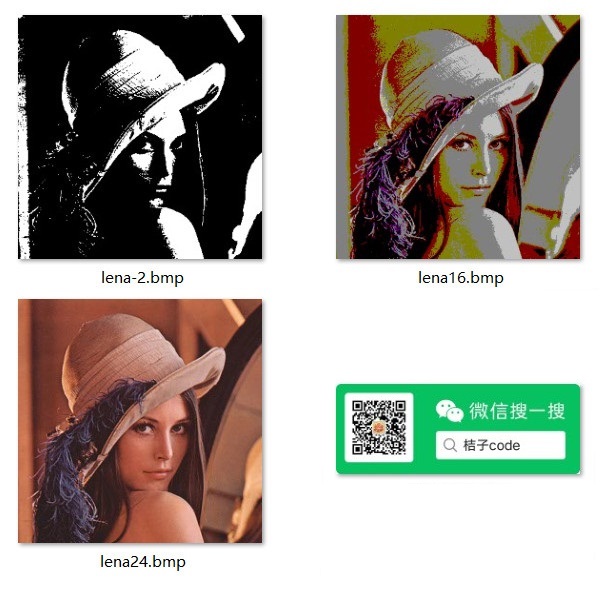
上面的3个lena图片都是bmp的后缀,从预览效果看它的内容是有差异的,这是图片文件内部编码方式存在差异导致的。2色图片中每个像素只需要1个bit表示,16色图中每个像素需要4个bit表示,而24位图中每个像素需要24bit表示,如果应用程序仅仅根据后缀来解码,就不能适应这种情况了。所以在文件内部的某个位置约定其具体的编码方式,这样应用程序就能根据这个约定决定使用何种解码方式。
桔子菌还想滔滔不绝地说下去,被橙子妹打断了: 前面说的不是文本文件么,怎么又扯到图片文件上来了,扯远了,赶紧回正题。桔子菌:不急不急,铺垫下而已,介绍些背景,接下来继续。
好了,回到开始说的文本文件,文本文件中存储的是字符,大多是人眼可识别的字符,比如英语字母、汉字、阿拉伯数字、罗马数字等等。计算机刚开始出现在英语世界的时候,最常用的是ASCII字符集,比如用数值65表示大写字母“A”,用数值48表示字符形式的数字“0”,ASCII字符集用数值0~127表示英文字母大小写、阿拉伯数字以及其他常用的符号。在英语世界里ASCII字符集能做到游刃有余,但是当计算机在全世界流行起来的时候,只用7个bit的128种数值就显得杯水车薪了,况且这128种数值已经被占用了。
这时候就出现了各种各样的字符集,比如汉字编码基本字符集GB2312,用2个字节表示一个字符,理论上就能表达65536(0xFFFF+1)种字符。当然咯,实际上GB2312只定义了94个区,每个区包含94个位,最多能表示94×94=8836个字符。GB2312用第1个字节表示区,第2个字节表示位,区的编号从1~94,位的编号也是从1~94,这是GB2312的字符集,但是表示字符时的编码需要在区和位的基础上分别加上0xA0,所以区和位的范围是0xA1~0xFE(0xA0+1~0xA0+94),这样2个字节中都没有使用小于0x7F的数值,也就能兼容ASCII编码。另外不知道是巧合还是故意为之,0xFF也不在其编码范围内,这一点貌似设计的比较巧妙,巧妙之处后面再说。虽然GB2312能表示8836个字符,但是实际存在一些空位,最终只收录了6763个汉字和682个非汉字图形字符,但是对付常用的汉字已经绰绰有余。

但是GB2312只是简体中文字符的编码标准,在台湾地区的繁体字用的是BIG5字符集,在日本则有S-JIS 、EUCODE 等字符集,这样同一个数值表示的含义在不同的字符集里表示的实际字符就会不一样。后来为了改变这个混乱的局面,ISO组织搞了个ISO10646、统一码联盟搞了个Unicode字符集,后来他们俩讨论决定只做一样的字符集,二者保持同步,意图将全世界的所有字符放在一个统一的字符集里面,每个字符都有自己唯一的“身份”。Unicode的出现为世间的编码灾难带来了曙光,但是”存在即合理”,历史存在的字符集已经存在了,各种应用程序为了向前兼容,仍然要支持老的字符编码标准。比如在简体中文系统里面,虽说新的应用程序已经支持Unicode字符集,但是GB2312依然在简体中文世界里大行其道。
桔子菌看着橙子妹欲言又止的样子,赶紧主动收拢了话题,没有扯更远的GBK,GB18030之类的汉字字符集了,况且GB2312也能说明问题了。到现在背景也介绍的差不多了,该来点实际的东西了。
再回到刚才的“联通”问题,用Windows自带的记事本保存的时候,默认保存的方式是“ANSI”方式(中文操作系统里实际上用的是GB2312编码标准,只是称呼上叫ANSI),点击记事本的文件菜单下的另存为,可以看到能选择不同的编码方式保存:

继续按照剩下的Unicode、Unicode big endian、UTF-8 三种编码方式另存为三个文件。再双击打开文件的时候这3个文件都能正常显示”联通”2个字符了。这中间发生了什么神奇的事情?
好了,到了该祭出神器的时候了,winhex软件是一款强大的二进制分析工具,不但可以分析磁盘启动区、修复文件,还可以用来查看文件的二进制内容,我们用winhex软件把前面保存的4种格式的文件打开看看。

第一部分是用ANSI方式存储的文件,打开后显示存储的数值是C1,AA,CD,A8,查看下”联”、”通”的GB2312编码,其数值分别为C1AA,CDA8,说明用ANSI方式保存就是用GB2312的编码方式存储的,下面2张图是GB2312的码表截图。


再继续看下”联通”的Unicode编码数值是多少,找一个“ Unicode编码”这类的工具网站,输入“联通”字符查询编码:
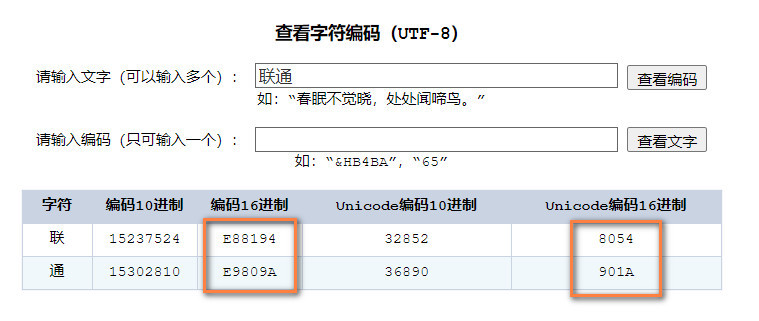
从上面的转换可以看到,右边橙色框是Unicode数值,”联”、”通”分别对应了0x8054和0x901a的Unicode编码值,正好和按照Unicode big endian方式保存文件的第三个字节开始的内容是一样的。而按照Unicode方式(实际是little endian)保存的文件内容和前者的顺序正好是”交替”存储的。关于big endian和little endian的区别,简单点说big endian就是高位字节的数据存储在低地址的模式,little endian则正好相反。用winhex打开文件看到的越往前是低地址,越往后是高地址,在big endian文件中可以看到”联”的高字节内容0x80排在前面低地址,低字节内容0x54排在后面高地址,而little endian正好相反。这也体现在最开始的2个字节上,big endian的是FE和FF,而little endian是FF和FE。
从Unicode的2种编码方式看,前面2个字节(BOM、字节序)并不是真正意义上的字符内容,它的作用相当于告诉应用程序这是采用Unicode方式编码的文本文件,并且表明后面的字节顺序用的是 big endian 还是 little endian 。这一点和图片文件类似了,用了些冗余的字节表明其编码方式,这样文本程序打开这种编码方式的文件时,就能正常识别编码方式并按照正确的姿势打开文件了。还记得在前面提到GB2312编码中没有0xFF的数值么,这里正好可以用来约定Unicode编码方式。
再来看下UTF-8编码方式,UTF-8并不是一种字符集,而是实现Unicode字符集的一种编码方式,实际上表示的还是Unicode字符集,可以形象地理解为Unicode字符集本身是一种“信源”编码,而UTF-8则是一种“信道”编码。RFC3629规定的Unicode字符集和UTF-8编码的对应关系是下图这样的,Unicode编码范围分为4个,每个范围内的字符对应了一种编码方式,比如在0x0000 0000~0x0000 007F之间的值需要1个字节表示,这样对于ASCII字符就只需要1个字节表示,做到了和ASCII字符集的兼容,而大多的汉字字符落在第3行的0x0000 0800~0x0000 FFFF范围内,需要用3个字节表示:

按照上面的规则计算下”桔子code”的UTF-8编码,首先查到“桔子code”的Unicode编码:
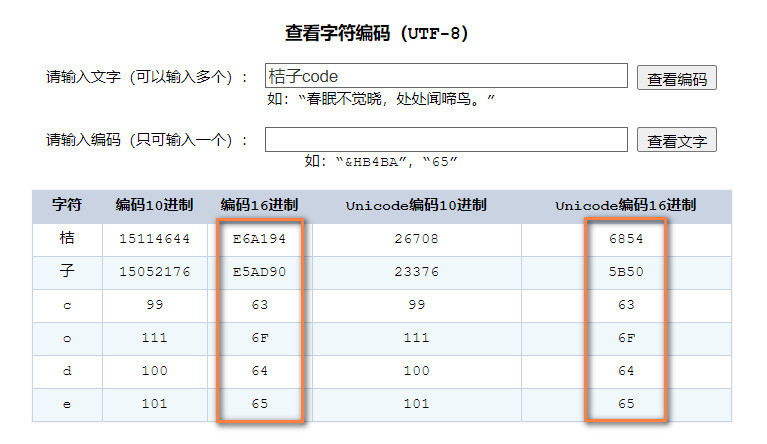
可以看到“code”这4个字符的Unicode编码范围在第1段0x0000 0000~0x0000 007F范围内,右侧橙色框中表示的Unicode编码和左侧橙色框的UTF-8编码是一样的,和ASCII编码也保持一致。“桔”的Unicode编码为0x6854,“子”的Unicode编码为0x5b50,下面来计算下是怎么对应到UTF-8编码的。首先找到”桔”的Unicode编码值落在第三行,将0x6854转换为二进制表示0b01101000 01010100,然后按照第三行范围对应右侧的方式进行切割,首先找到最右侧的6个bit:010100,再往左找6个bit:100001,然后还剩下左边的4个bit:0110。将这3段二进制数值从右往左依次填入,就可以得到0b11100110 10100001 10010100,换算成16进制,得到的结果为0xE6A194,换算的结果和网页上查到的UTF-8编码值是一样的。”子”的计算过程是一样的。
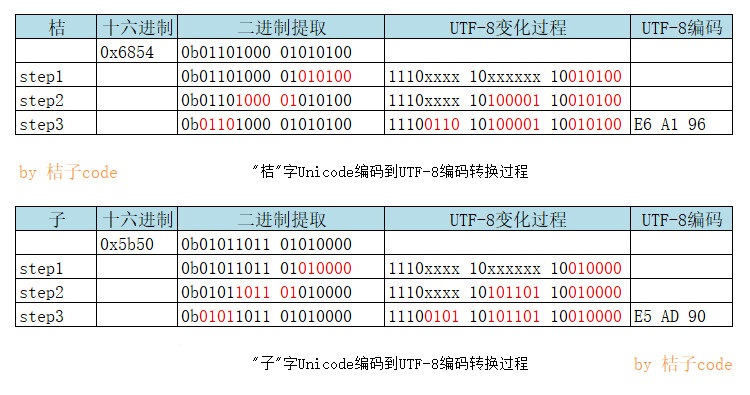
用同样的方法可以计算出“联通”2个字符的UTF-8编码值,再回来看保存了“联通”2个字符的文本文件时,其正式编码值0xE88194 和0xE9809A 前面多出了 EF,BB,BF 3个字节的内容,这3个字节用来表示这个文本文件用的是UTF-8编码方式,和用Unicode的2种编码一样也是一种BOM(字节序)。
桔子菌长长地叹了一口气:终于把背景介绍的差不多了,现在要来填最开始的那个坑了。
由于历史的原因,文本文件出现的时候并没有像图片文件那样在文件内部约定其编码方式,只是后来新出现了其他的编码方式之后才开始有些约定,比如Unicode的大端模式和小端模式,分别在文件头用了FEFF或者FFFE表示这是一种Unicode的编码方式,而带BOM的UTF-8编码方式在文件中则用EFBBBF表示是一个带BOM的UTF-8编码,但是这仅仅是带BOM的,还有些文件是可以不带BOM的UTF-8编码方式。当文本程序打开一个文本文件时,如果没有在文件内部指明采用哪种编码方式,它就会采取“猜测”的方式去判断可能使用的编码方式,在“猜测”的时候就有可能出错了。
我们来看看可能的情况,只能说是可能,因为没有拿到程序的源码抓bug那是耍流氓。前面查到“联通”2个字的GB2132编码为C1AA,CDA8,转换成二进制就是0b1100000110101010 ,0b1100110110101000,恰好能被误解为2字节的UTF-8编码:
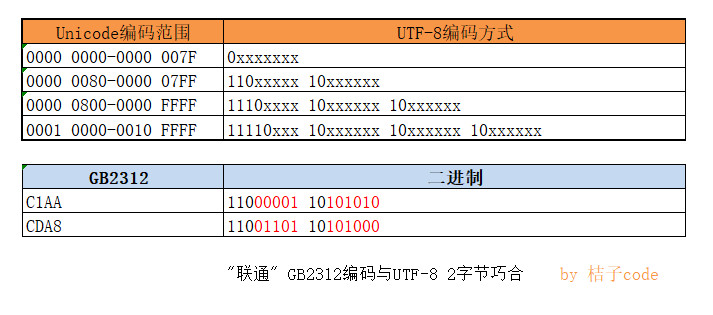
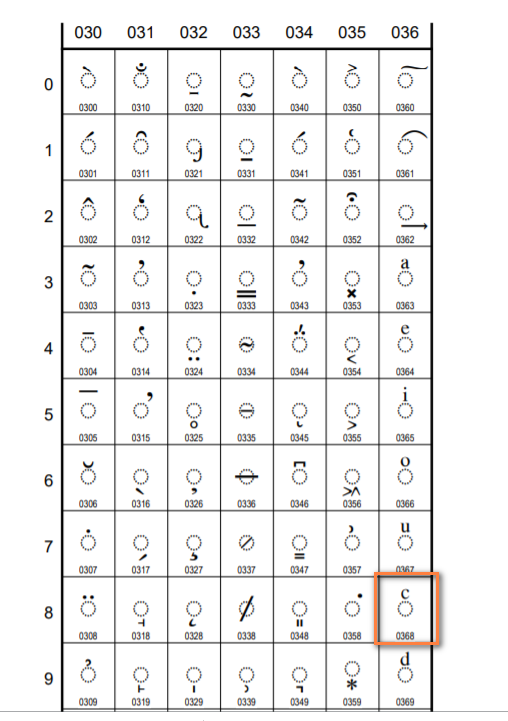
如果当成2字节UTF-8,提取其中有效bit位构成的Unicode编码为:0x006a,0x0368,按道理前者对应的是字母”j”,但是记事本程序可能并不能理解2字节宽度的0x006a,所以显示的是乱码,而后者查到的Unicode字符是下图这样的,可能操作系统中没有相应的字体也会显示出乱码来:
桔子菌讲得口水都干了,现在也差不多到了总结的时候了:今天讲了这么多,从一个记事本程序的bug聊到了ASCII,GB2132,Unicode,UTF-8,这一大堆概念中有些是字符集、有些是编码方法,有些是国标、有些是ISO标准。比如ASCII即是字符集,自身也包含了编码方法,所以有时说ASCII字符集,有时候说ASCII编码,其实是一个意思,Unicode是字符集,而UTF-8则是Unicode的编码方法。关于不能正常显示文件内容的问题,就是因为存在各种编码标准,而文本文件又没有约定内部某个字节表示其采用哪种编码方式,所以应用程序就只好去猜测文件用哪种编码方式,就会出现猜错的情况。橙子妹听完似有所悟,表示对字符编码有了个大概的了解,另外对桔子菌这么能扯表达了滔滔不绝的敬仰之情。
橙子妹回到电脑前也新建了个联通的txt文件玩一下,但是发现并没有出现不能正常显示的问题。桔子菌在一旁提醒道:这可是30年的老bug了,微软良心发现”终于做出这个决定”,在30年之后还是把这个bug修复了,所以在Windows10 1909之后的版本不存在这个问题了。
推荐阅读: Windows PATH变量、命令行、搜索路径 好冷的Python–源文件编码 用你的邮箱为你看家护院 好冷的Python-- if __name__==’__main__’是啥东东 zbar:给我来10G打码图片