原文链接:http://www.juzicode.com/python-error-bytes-decode-unicodedecodeerror-utf-8-codec/
错误提示:
bytes类型的数据使用decode()方法解码时提示:UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xbd in position 0: invalid start byte
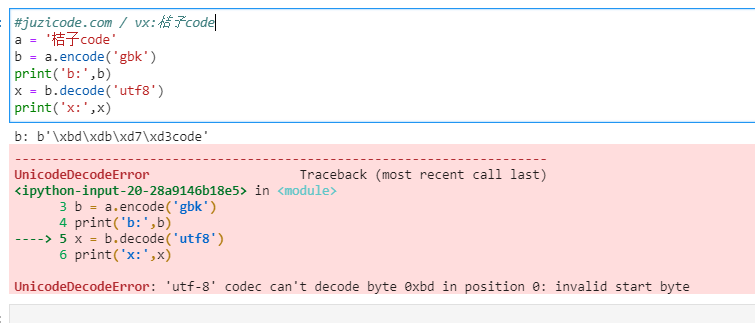
#juzicode.com / vx:桔子code
a = '桔子code'
b = a.encode('gbk')
print('b:',b)
x = b.decode('utf8')
print('x:',x)==========运行结果:
b: b'\xbd\xdb\xd7\xd3code'
-----------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
in
3 b = a.encode('gbk')
4 print('b:',b)
----> 5 x = b.decode('utf8')
6 print('x:',x)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbd in position 0: invalid start byte
错误原因:
1、变量b的编码方式是gbk,解码时却采用了utf8解码。
解决方法:
1、修改解码方式为gbk。
#juzicode.com / vx:桔子code
a = '桔子code'
b = a.encode('gbk')
print('b:',b)
x = b.decode('gbk')
print('x:',x)==========运行结果:
b: b'\xbd\xdb\xd7\xd3code'
x: 桔子code
扩展内容:
如果本文还没有完全解决你的疑惑,你也可以在微信公众号“桔子code”后台给我留言,欢迎一起探讨交流。
