原文链接:http://www.juzicode.com/python-tutorial-pop3/
在 Python进阶教程m9b–网络通信–smtplib发送邮件 一文中桔子菌给大家介绍了怎么用Python发送邮件,俗话说“来而不往非礼也”,有发就要有收,这篇文章将带大家熟悉下怎么用poplib和email模块接收邮件。
先做好准备工作,仍以163邮箱为例,首先需要先设置好邮箱的授权码,并找到邮箱的pop3服务器地址:

1、创建POP3()实例、登录
首先手动输入接收邮箱的地址和授权码,这里我们用到了getpass模块接收键盘输入的密码,这样密码不会显示在屏幕上,对比input()函数更安全些。
#输入邮箱地址、密码
to_addr = input('输入收件人: ')
password = getpass.getpass('收件人邮箱密码: ')==========运行结果:
-----欢迎来到www.juzicode.com
-----公众号: 桔子code/juzicode
输入收件人: xxx@163.com
收件人邮箱密码: ####这里因为使用getpass.getpass()方法,密码不显示和接收邮件一样,传入pop3服务器地址“pop.163.com”创建一个POP3()实例,为了方便查看通信过程设置好调试打印等级,一般设置到2。因为创建POP3()实例会和服务器发起连接,这里用try语句捕获可能的异常。
#连接邮箱,设置调试等级
try:
pop3 = poplib.POP3('pop.163.com')
pop3.set_debuglevel(1)
print(pop3)
except:
print('连接服务器失败')
sys.exit(1)使用pop3.user()传入邮箱地址 和 pop3.pass_()方法传入授权码或邮箱密码(注意pass_()方法有下划线!), user() 和 pass_()方法会发起连接,可能会登录失败,也用try语句捕获异常。
#登录邮箱
try:
ret=pop3.user(to_addr)
print(ret)
ret=pop3.pass_(password)
print(ret)
except :
print('登录邮箱失败')
sys.exit(1)
print('登录邮箱成功')==========运行结果:
*cmd* 'USER xxx@163.com'
b'+OK core mail'
*cmd* 'PASS xxx'
b'+OK 5 message(s) [17765 byte(s)]'
登录邮箱成功2、解析邮件
前面的过程完成了邮箱登录,下面开始读取和解析邮件。
2.1、获取邮件列表
用pop3.list()方法获取邮件消息列表,返回的是一个三元组:(response, [‘mesg_num octets’, …], octets) :
#获取邮件清单
mail_list = response, listings, octets = pop3.list()
print(mail_list)==========结果:
*cmd* 'LIST'
(b'+OK 5 17765', [b'1 3429', b'2 10596', b'3 879', b'4 1481', b'5 1380'], 40)listings = [b’1 3429′, b’2 10596′, b’3 879′, b’4 1481′, b’5 1380′] 这个列表就是我们需要的关键信息,表示获取到的邮件列表,包含了5个元素表示有5封邮件,b’1 3429′ 表示第1封邮件有3429字节, b’2 10596′ 表示第2封邮件,以此类推。每个元素内部由空格分隔,前面的数字表示mesg_num,这个值就是后面解析时用来表示的邮件索引号。敲黑板,这个是关键变量!
接下来开始遍历邮件列表listings,对它的单个元素用split()方法切割出mesg_num。另外因为返回的是bytes类型的数据,为了方便后面的处理,我们将其转换为str类型:
for listing in listings:
print('~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~')
#提取邮箱列表信息
mesg_num, size = listing.split()
mesg_num = bytes.decode(mesg_num)
size = bytes.decode(size)
print(mesg_num,size)有了这些邮件消息编号,接下来就可以利用这些编号提取邮件header和正文等内容。
2.2、获取邮件Header
首先用pop3.top()方法提取邮件Header,top()方法输入的是邮件列表里解析出来的mesg_num。返回结果也是一个三元组,中间的lines是关键信息,因为是bytes类型,所以也需要转换为str类型。
#提取邮件头
res = response, lines, octets = pop3.top(mesg_num, 0)
#print(lines)
lines_post=[]
for l in lines:
lines_post.append(bytes.decode(l))接下来用email.message_from_string()构造结构化数据,再提取From,To,Subject,Date等信息:
#构造message
message = email.message_from_string('\n'.join(lines_post))
print('type(message):',type(message))
print('From:',message['From'])
print('To:',message['To'])
print('Subject:',message['Subject'])
print('Date:',message['Date'])==========结果:
4 1481
*cmd* 'TOP 4 0'
type(message): <class 'email.message.Message'>
From: xxx <xxx@163.com>
To: xxx <xxx@163.com>
Subject: https://www.juzicode.com/ vx:juzicode
Date: Wed, 11 Nov 2020 20:08:18 +0800 (CST)2.3、获取邮件正文
用pop3.retr()方法提取邮件正文, retr()方法输入的也是邮件列表里解析出来的mesg_num。返回结果也是一个三元组,中间的lines是关键信息,因为是bytes类型,所以也需要转换为str类型。
#提取邮件内容
res = response, lines, octets = pop3.retr(mesg_num)
lines_post=[]
for l in lines:
lines_post.append(bytes.decode(l))接下来用email.message_from_string()构造结构化数据,这里我们先不考虑复杂的情况,先只处理类型为multipart和text类型的内容。
根据get_content_maintype()方法获取到不同的类型,需要做分支处理。如果是multipart,需要再次遍历;如果是text类型,就可以直接用get_payload()获取邮件正文。
这个例子中邮件内容的解码mail_content.decode() 尝试了UTF8和GBK 2种方式,也可能是其他编码方式,需要根据实际情况作出变化。
#构造message
message = email.message_from_string('\n'.join(lines_post))
maintype = message.get_content_maintype()
print('maintype:',maintype)
if maintype == 'multipart':
for part in message.get_payload():
print('multipart:',part.get_content_maintype())
if part.get_content_maintype() == 'text':
mail_content = part.get_payload(decode=True).strip()
try:
print('mail_content:',mail_content.decode('UTF8'))
except:
try:
print('mail_content:',mail_content.decode('GBK'))
except:
continue
elif maintype == 'text':
mail_content = message.get_payload(decode=True).strip()
try:
print('mail_content:',mail_content.decode('UTF8'))
except:
try:
print('mail_content:',mail_content.decode('GBK'))
except:
continue ==========提取第5封邮件的结果:
*******************
*cmd* 'RETR 5'
maintype: multipart
multipart: text
mail_content: www.juzicode.com 微信公众号:桔子code
multipart: text
mail_content: <div style="line-height:1.7;color:#000000;font-size:14px;font-family:Arial"><p style="margin:0;">www.juzicode.com&nbsp; &nbsp;微信公众号:桔子code</p></div><br><br><span title="neteasefooter"><p>&nbsp;</p></span>从网页进入邮箱看到的邮件内容是下图这样的,正好和前面第一次取到的text内容是一样的:“mail_content: www.juzicode.com 微信公众号:桔子code”
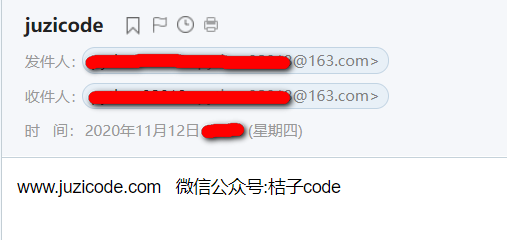
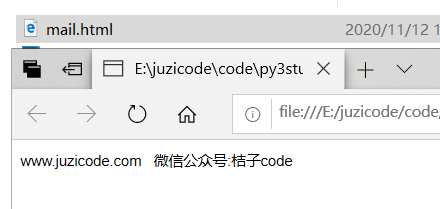
第2次取到的text内容则是html格式的邮件正文,我们可以创建一个文本文件,输入这段内容:<div style …… /p>,改后缀为html,然后用浏览器打开,看到的效果和第1次取得的text内容是一致的:
2.4 处理附件和复杂的邮件正文
上一节中处理邮件内容作了简化操作,比如解析文本内容的时候采用的是尝试按照UTF8和GBK 2种方式解码,不能完全自适应解析;如果邮件中有附件,也没有实现接收附件的功能 ;当message的主类型为multipart,只处理了2层,实际情况可能更复杂。接下来继续改造解析消息方式,因为multipart可能有多层,需要用递归来实现,我们定义一个parse_msg()的函数。
如果邮件带有附件,首先利用get_filename()方法获取附件文件名称,如果这个名称非空,则说明该段message是个附件,通过get_payload()方法可以提取出数据,并将该数据写入到文件中:
#如果get_filename()返回非None,表示有附件
filename = message.get_filename()
if filename:
print('找到1个附件,文件名:',filename)
data=message.get_payload(decode=True)
with open(filename,'wb') as pf:
pf.write(data)
return filename通过放开调试打印,我们可以看到邮件正文使用的字符集(编码方式): b’Content-Type: text/plain; charset=GBK\r\n’,利用get_content_charset()方法就能获取到邮件正文的编码方式 ,如果是消息主类型为text,则可以用该编码方式解析:
#如果主类型为text,根据编码方式解析
content_charset = message.get_content_charset()
print('content_charset:',content_charset)
if maintype == 'text':
mail_content = message.get_payload(decode=True).strip()
try:
print('mail_content:\n',mail_content.decode(content_charset))
except:
print('解码邮件错误') 如果主类型是multipart,则调用自己,实现递归解析消息:
elif maintype == 'multipart':
for message_part in message.get_payload():
parse_msg(message_part) 完整的消息解析函数:
def parse_msg(message):
type = message.get_content_type()
maintype = message.get_content_maintype()
subtype = message.get_content_subtype()
print('type:',type)
print('maintype:',maintype)
print('subtype:',subtype)
boundary = message.get_boundary()
print('boundary:',boundary)
#如果get_filename()返回非None,表示有附件
filename = message.get_filename()
if filename:
print('找到1个附件,文件名:',filename)
data=message.get_payload(decode=True)
with open(filename,'wb') as pf:
pf.write(data)
return filename
#如果主类型为text,根据编码方式解析
content_charset = message.get_content_charset()
print('content_charset:',content_charset)
if maintype == 'text':
mail_content = message.get_payload(decode=True).strip()
try:
print('mail_content:\n',mail_content.decode(content_charset))
except:
print('解码邮件错误')
#如果主类型为multipart,递归
elif maintype == 'multipart':
for message_part in message.get_payload():
parse_msg(message_part)
return 这是解析其中一封邮件的过程:
*cmd* 'RETR 5'
type: multipart/mixed
maintype: multipart
subtype: mixed
boundary: ----=_Part_70354_1982485947.1605182620221
content_charset: None
type: multipart/alternative
maintype: multipart
subtype: alternative
boundary: ----=_Part_70356_1595858516.1605182620221
content_charset: None
type: text/plain
maintype: text
subtype: plain
boundary: None
content_charset: gbk
mail_content:
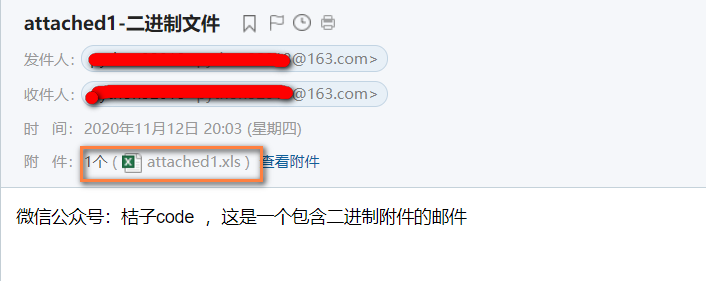
微信公众号:桔子code ,这是一个包含二进制附件的邮件
type: text/html
maintype: text
subtype: html
boundary: None
content_charset: gbk
mail_content:
<div style="line-height:1.7;color:#000000;font-size:14px;font-family:Arial"><p>微信公众号:桔子code ,这是一个包含二进制附件的邮件<br></p></div><br><br><span title="neteasefooter"><p> </p></span>
type: application/vnd.ms-excel
maintype: application
subtype: vnd.ms-excel
boundary: None
找到1个附件,文件名: attached1.xls进入邮箱看到的邮件正文、附件和前面解析到结果是一样的:
总结:到这里整个接收邮件的过程就介绍完了,主要是2大步骤:第一步poplib模块接收邮件:创建连接实例、登录、获取邮件头、获取邮件正文;第二步用email模块进行邮件内容的解析。
推荐阅读: Python进阶教程m9–网络通信–socket通信 Python进阶教程m9b–网络通信–smtplib发送邮件